Media Image

L'Open Expertise !
Au milieu des années 1990, avec l'arrivée d'Internet et des premiers courriels en France, peu après l'avènement de la première vidéo Youtube en 2005 ; les accès aux contenus multimédia par le Web, jusqu'alors limités avec le stockage physique domestique (CD, disques durs, clés USB, cartes SD, etc), explosent et offrent des possibilités d'accès bien plus avantageuses.
Lors de l'apparition des smartphones et tablettes, Internet connaît un volume toujours croissant d'échanges de données sous forme de photos, vidéos, documents. Échangées chaque jour avec les proches, les administrations, les établissements scolaires, les données personnelles transitent par d'innumérables serveurs ou y résident durablement quelque part, au point de ne plus savoir où elles se trouvent exactement.
Aujourd'hui, ces flots de données privées relèvent d'un facteur commun : leur stockage sur les services en nuage. Peu-à-peu offert par les géants de la tech, leurs services au grand public (Dropbox, Apple iCloud, Amazon S3) reposent sur une technologie commune peu connue dans le monde Informatique, il s'agit du “Stockage Objet”, en plein essor.
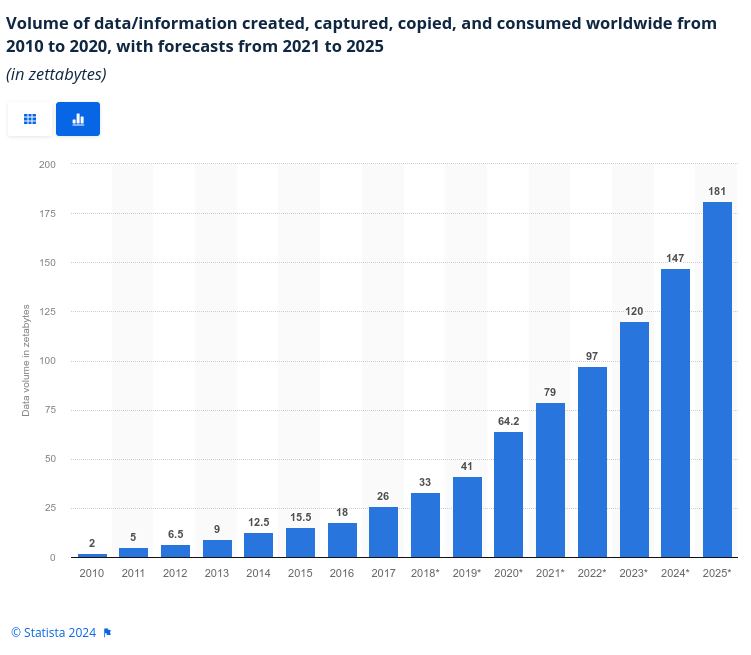
Avec une fréquence de génération de 402.74 millions de téraoctets de données par jour en 2024, avec une explosion prévue sur l'année 2025 ; le Stockage Objet prend les devants et mise sur la généralisation de son usage afin de réduire son coût.
Cette technologie est la plus utilisée et se retrouve derrière les services proposés par les plateformes de streaming, collaboratives ou de diffusion, de stockage de données pour l'IA (Intelligence Artificielle), pour n'en citer qu'une partie. Elle est le fruit du travail de normalisation du stockage, de son accès et de la préservation des données au niveau régional ou mondial, par les fournisseurs de services en nuage.
Il offre une alternative au stockage classique, difficile à maintenir, et augmente les capacités de l'ordre du Peta au Zeta octet (1000 milliards de fois la taille d'une simple clef USB d'un Go), et permet à tout utilisateur la capacité de déposer et d'accéder aux fichiers sur le web, privilège autrefois à la seule portée des techniciens informatique. Il apporte des nouvelles caractéristiques :
Un nombre important d'acteurs et d'écosystèmes reposent sur le stockage objet. Certaines offres dites "managées", sont prêtes à l'emploi. D'autres solutions, open source, permettent l'auto-hébergement pour une meilleure maîtrise. Pour aller plus loin, lire notre article qui dresse un panorama des solutions disponibles.
OpenStack Swift est un logiciel de stockage objet en nuage (en ligne, à distance) tolérant aux pannes, au même titre qu'Amazon S3. Aujourd'hui, il fait partie de l 'écosystème Openstack supporté par la Fondation OpenStack .
Il permet le stockage et la récupération de données non-structurées (images, vidéos, sites web statiques) via une API REST (interface de programmation qui permet d'établir une communication entre deux applications), de manière sécurisée et distribuée sur un ensemble de serveurs.
C'est un système évolutif, dit élastique, qui garantit la concurrence d'accès dans un environnement très sollicité, permet l'ajout dynamique de capacité de stockage, sans interruptions de service ou dégradations des performances ; les données sont répliquées sur plusieurs serveurs afin de palier aux défaillances/pannes disques, réseaux ou serveurs.
De nombreuses déclinaisons de déploiement existent :
Dans le cadre de cet article, nous avons déployé chacune d'entre elles, afin d'en délimiter leurs domaines d'utilisation.
Notre expérimentation en laboratoire reproduit à volonté un cluster multi-région à haute disponibilité, compatible avec une demande croissante d'objets, pour documenter sa maintenance, son utilisation et consolider les performances. Cette plate-forme comporte trois points d'accès (swift-proxy), trois regions (datacenters) et trois zones par région (armoires de serveurs).
Le déploiement, l'installation des serveurs et la configuration des services sont automatisés avec Terraform et Ansible. Sans outil "kolla-ansible" (fourni par OpenStack) de manière à appréhender les différents services et leurs articulations pour une meilleure maîtrise du sujet. Bien qu'elle s'appuie sur des composants simples comme rsyncd et le langage de programmation Python, cette architecture reste complexe à mettre en œuvre et nécessite une période de recette pour l'adapter aux réels besoins.
Les fonctionnalités que nous avons exploitées et testées :
Les outils et librairies que nous avons testés :
Interfaces en ligne de commande (CLI) tels que Swift / OpenStack, modules python swift / keystone, clients S3 (awscli, s3cmd) et curl.
Une fois pris en main et bien configuré, le couple Swift - Keystone se révèle robuste, facile d'utilisation et transparent pour l'utilisateur grâce aux API.
De nombreuses opportunités se sont présentées, pour se familiariser avec les mécanismes internes au stockage objet Swift comme les concepts de dispersion, réplication, priorisation - découpage d'objets par segments et politiques de stockage.
statsd constitue la solution de monitoring nativement disponible dont Graphite permet la visualisation.
Ces travaux sont capitalisés dans la documentation, le code Terraform et les rôles Ansible, pour tous les usages ultérieurs.
Kenny qui a participé à l'étude, nous donne son retour :
Il y a moins d'un mois, je ne connaissais pas du tout OpenStack/Swift. En tant que software engineer, voici mon vécu et mes connaissances de cette appréhension de la plate-forme dont notamment son utilisation côté client et la gestion des objets 'larges'. J'ai pu documenter l'utilisation côté client qui est relativement simple pour les habitués des lignes de commandes ou des requêtes http. Ce sont les deux principales manières de communiquer avec la base de données SWIFT.
Sur la partie administrative, il y a bien sûr plus de travail à fournir afin de maintenir de bonnes performances, d'assurer la pérénité des données et de garder une plate-forme qui puissent s'adapter à des objets de toutes tailles. A condition de bien configurer les politiques de stockage (Storage Policies) !
Afin d'utiliser correctement la CLI Swift, beaucoup de paramètres sont à définir, même pour une simple opération comme le listing des conteneurs ou des objets, que ce soit en ligne de commande `swift` ou par des requêtes HTTP. Pour gagner du temps, notamment dans l'ecosystème SWIFT, faire des scripts peut faire gagner énormement de temps pour mieux visualiser l'ensemble ou une partie du cluster, comme par exemple pour visualiser la hiérarchie des conteneurs, des objets, leurs tailles, les noeuds dans lesquels ils sont stockés, la répartition des poids dans le cluster, etc.
Les technologies comme la 5G, le Big data et l’intelligence artificielle participent déjà à la gigantesque génération de données qui ont recours à des solutions de stockage autrefois réservées au domaine spatial (astronomie, calculs scientifique, etc). Le stockage objet est en effet apparu à l'origine pour les besoins de développement des projets spatiaux (NASA).
Aujourd'hui, rien qu'à l'échelle européenne ces projets dans le domaine spatial lancent les travaux d'hyper-connectivité. Services de mobilité 5G/6G cryptés et Internet des objets pour tous les citoyens au niveau mondial, une propulsion dans l'ère quantique et un nouveau palier de production de données titanesque. Pour aller plus loin : Le NewSpace (Agenda 2025 de l'ESA).
Il semblerait que la science soit à l'origine de notre capacité à gérer et générer des données à l'infini et au delà ... sera-t-elle en mesure de nous apporter la solution pour leurs stockage en quantités astronomiques ... un futur centre de données sur la face cachée de la lune pour nos photos de chats ? Est-ce la raison des récentes courses aux explorations spatiales par la Chine, l'Inde, Russie, USA ?
{kind=link}
{kind=link}